

Web Tutorials
Accessing a URL from the Browser
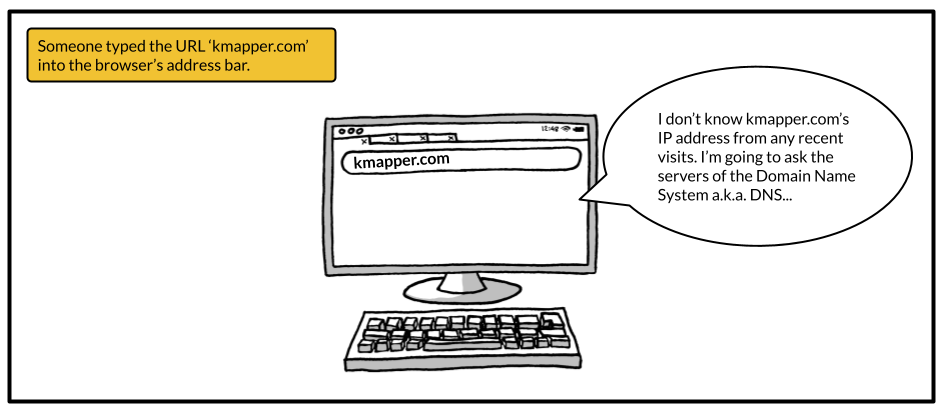
You enter a URL into the browser's address bar and hit ‘Enter'. The first thing the browser does is following a certain procedure to find the actual Internet Protocol address of the server having access to the content of the website you are trying to visit.
I'm sure you have already heard of the Internet Protocol address as the IP address. The IP address is just a number uniquely identifying a server connected to the internet, which is just a network of computers using this Internet Protocol to communicate with each other. Don't worry about the Internet Protocol, the details of IP addresses or the procedure of getting these. Getting IP addresses involves your browser communicating with different servers of the Domain Name System a.k.a. DNS. However, this is one of the rabbit holes you don't need to go down for now.
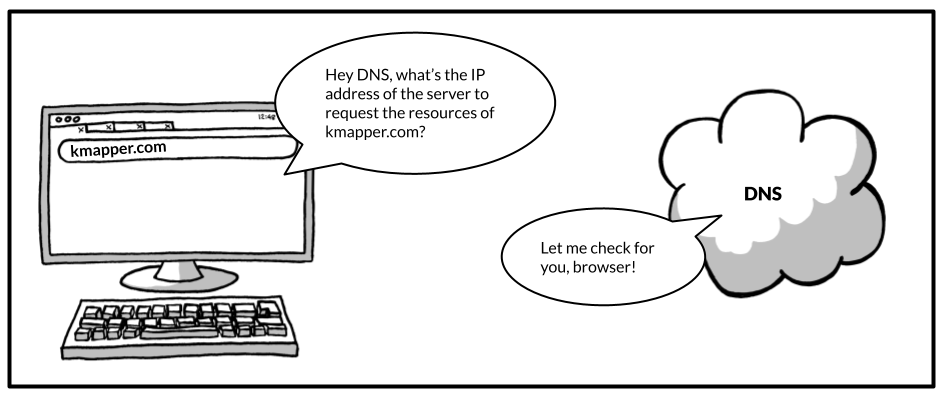

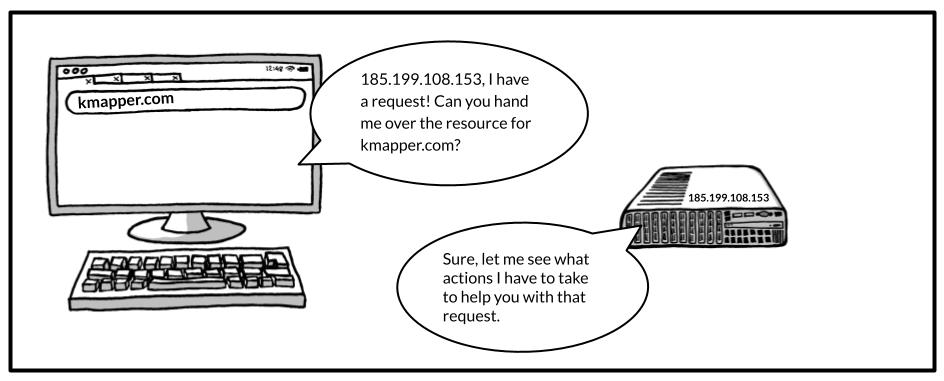
Once your browser knows the IP address of the server it needs to communicate with, it goes along and sends a so-called request to this server. The browser basically asks for an initial response from the server which tells the browser what to display and whether to request additional resources or not.
The server on the other hand will check what actions have to be taken to answer the browser’s request. Maybe the resource the browser is asking for is already prepared and ready to be served so the server can respond right away. Or the request is handed over to the so-called backend of the website you are trying to visit. No need to go into the details of the backend. Just note that in the backend an endless variety of different processes could take place to create the response to the browser’s request. This might involve checking whether you are authorized to request the resource at all. It might also involve querying one or several databases, making additional requests to other servers, performing some calculations, etc.
Assuming you are authorized to make the request and you are visiting a regular website with content for humans (as opposed to content for other computer programs), the server will probably answer the request with an HTML (Hypertext Markup Language) response. For now, don't worry about the details of HTML. It's just one way of formatting website content so your browser can easily read it.
You should know, however, that this initial HTML response usually lists additional URLs with resources your browser will need to request as well in order to correctly display the website you are trying to visit. This includes images, CSS (cascading style sheets) with information about how to style the content of the website (e.g. colors, font sizes, spacings between paragraphs, etc.), and JavaScript code with instructions on how to interact with the website (what should happen when clicking a button, etc.). So, your browser goes through this HTML response, checks for URLs of additional resources listed, and requests all the listed resources in the same manner as it did before. By the way, these additional resources might or might not be located at the same IP address the initial request was made to. As before, for now, don't worry about how CSS and JavaScript works.
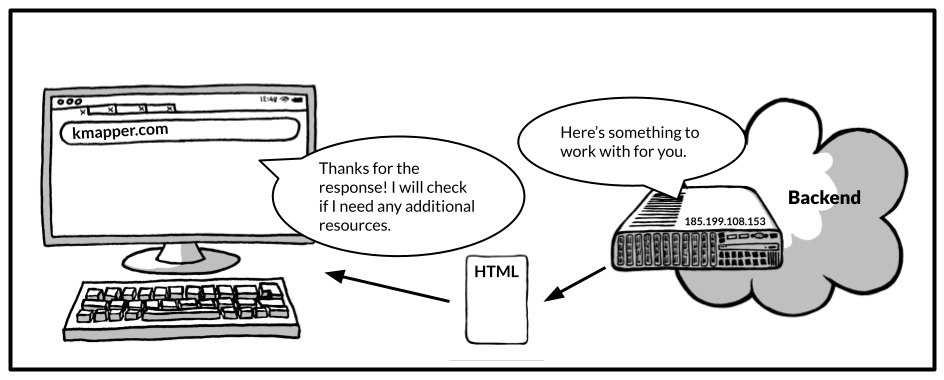
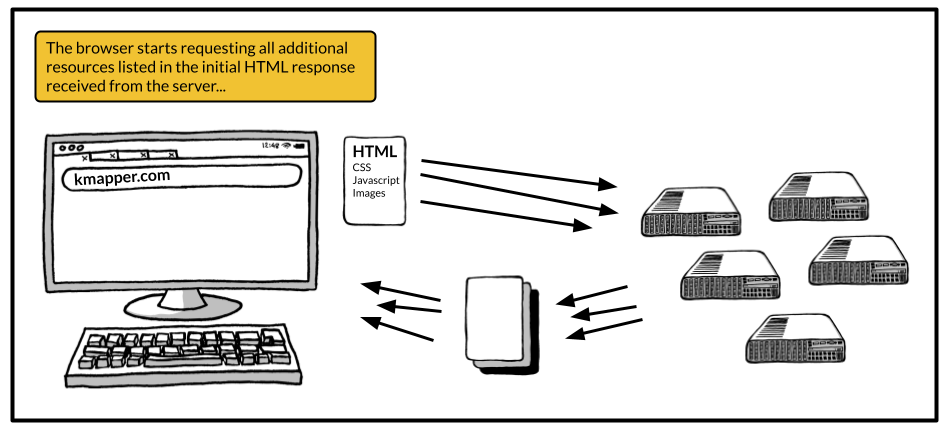
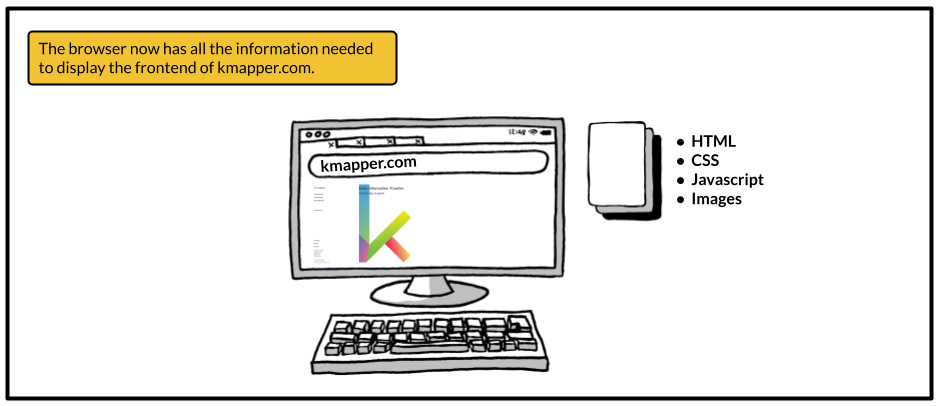
By now, your browser has made all the needed requests and, hopefully, got back responses with all the needed resources to display the website to you. All these resources now live on your computer, making up the frontend of the website which you interact with.
Side Note
This little tutorial is motivated by a misconception I sometimes encounter regarding websites. When you enter a URL into the browser's address bar and hit ‘Enter’, you don't point your browser to the server of the website and somehow look at the website currently running on that server. Your browser really just grabs the needed information from the server, saves them to your computer, and displays everything to you.
Now you might say: "Wait a minute, our company uses Google Analytics and there I can exactly see how many people are currently on our website and how they interact with it! What's going on there? They are clearly on our website."
If your website makes use of Google Analytics, the browsers of your website visitors request some Google-provided Javascript code when accessing your website (as part of the additional resources needed for the website). This code is actually a computer program run by the browsers of your website visitors. It's also telling their browsers what to do when they, for example, click somewhere on the website. Each time they click somewhere, the program instructs their browsers to send some information to the Google Analytics servers. This might include information about what they have clicked on, how far down the page they have scrolled, what kind of browser they are using, etc. Your Google Analytics dashboard on the other hand, constantly requests its own servers in order to show you the newest data received from all your visitors’ browsers. As long as your website visitors are interacting with the website they have requested from your server, their browsers are also sending data to the Google Analytics servers. Therefore, Google Analytics will tell you someone is currently on your website. However, it's programs run by the browsers of your website visitors which capture their actions and send the information to the Google servers.